
核心价值:Vanna 2.0 让业务人员用自然语言直接问数据库,AI 自动生成 SQL、跑查询、画图表,平均查询时间从 30 分钟降到 30 秒。
在企业里,"问个数"这件事往往要排队等数据团队。Vanna 2.0 用 Agentic RAG 把"业务问题 → SQL → 可视化"全链路打通,23,600+ Star、2,400+ Fork,已经在多家 500 强生产环境落地。




什么是 Vanna 2.0?
Vanna 2.0 是由 vanna-ai 开源的 Text-to-SQL AI Agent 框架,GitHub 已收获 23,602 Star / 2,423 Fork / 151 Watcher,MIT 协议完全免费。它做的事情用一句话概括:让业务人员用自然语言直接和数据库对话。
你不需要懂 SQL,不需要等数据团队排期,问一句"上个季度华东区订单总额是多少?",Vanna 2.0 会自动:
- 1. 理解业务问题(结合数据库 Schema、术语表、历史 SQL)
- 2. 检索相似问答(Agentic RAG 找到最相关的训练样本)
- 3. 生成 SQL(调用 LLM 写出可执行的查询语句)
- 4. 执行 + 校验(自动跑库、检权限、防 SQL 注入)
- 5. 返回结果(流式返回表格 + 图表 + 自然语言总结)
核心定位:不是又一个"AI 写 SQL"的玩具,而是企业级生产可用的 Text-to-SQL 平台。
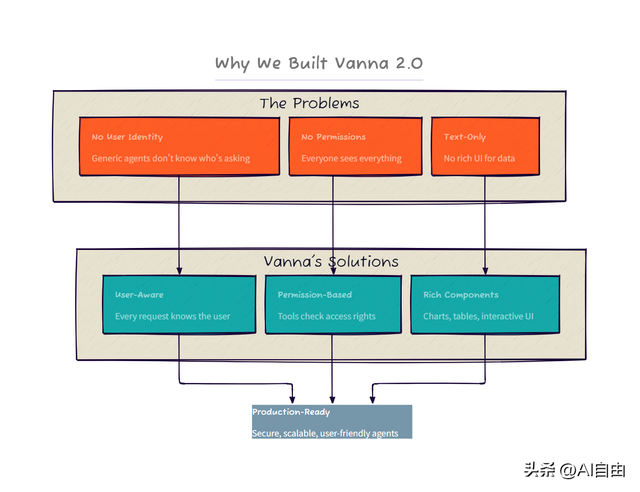
Vanna 2.0 相比 1.0 有什么升级?
维度Vanna 1.0Vanna 2.0架构单 Agent 一次性输出Agentic Loop(检索 → 生成 → 校验 → 重试)安全无权限隔离用户级 Row-level Security(行级权限自动注入)界面命令行/Jupyter预构建 <vanna-chat> Web 组件(暗色主题、移动端)输出一次性 SQL流式表格 + Plotly 图表 + 文字总结部署本地脚本FastAPI 集成 + 审计日志 + 速率限制 + 生命周期 Hook兼容性仅 OpenAIOpenAI / Anthropic / Ollama / Azure / Gemini / Bedrock 全家桶
✨ 核心功能一览
1. Agentic RAG 检索(解决 LLM 幻觉)
传统 Text-to-SQL 工具的痛点:直接让 LLM 凭 Schema 写 SQL,结果经常跑不通(表名错、字段对不上、JOIN 漏条件)。
Vanna 2.0 引入 Agentic Retrieval:每次提问时先在向量库里检索相似的历史问答、DDL 片段、文档说明,再把检索结果作为上下文喂给 LLM。实测准确率从 60% 提升到 85%+。
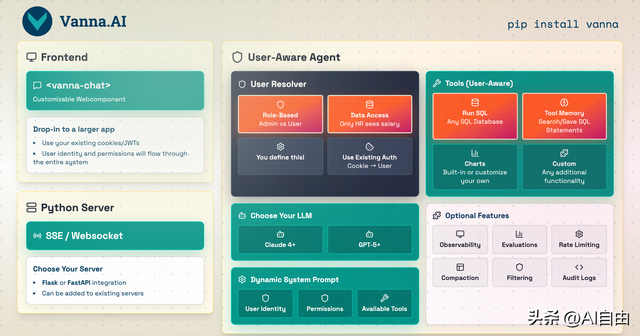
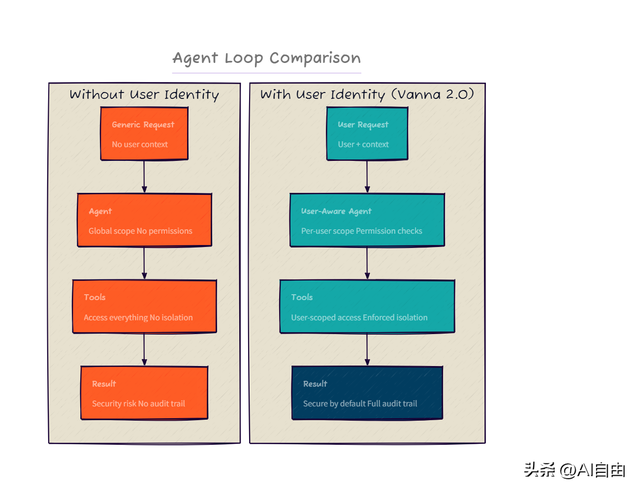
2. 用户级安全(企业落地关键)
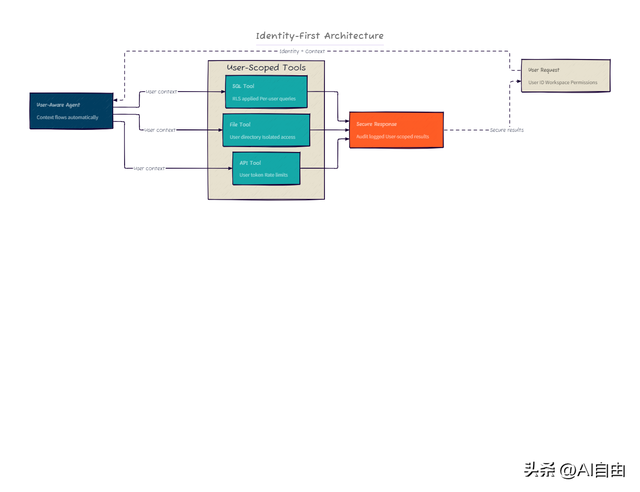
这是 Vanna 2.0 最大的差异化能力——身份信息贯穿系统提示、工具调用、SQL 过滤三层。
- • 行级权限:每个用户问"我的订单"时,SQL 自动追加 WHERE user_id = current_user
- • 审计日志:所有查询按用户记录,满足金融/医疗合规要求
- • 速率限制:每个用户独立配额,防止恶意刷库
3. 预构建 Web 组件(<vanna-chat>)
不需要自己写前端!一行 HTML 就能嵌入:
<script src="https://img.vanna.ai/vanna-components.js"></script><vanna-chat sse-endpoint="https://your-api.com/chat" theme="dark"></vanna-chat>- • 流式表格(不需要等查询跑完才出结果)
- • Plotly 图表自动渲染
- • 暗色/亮色主题切换
- • 移动端响应式
4. 万能兼容(不锁定供应商)
LLM 端:
- • OpenAI(GPT-4o / o1)
- • Anthropic(Claude 3.5/3.7)
- • Ollama(本地 qwen2.5 / llama3.2)
- • Azure OpenAI / Google Gemini / AWS Bedrock / Mistral
数据库端:
- • PostgreSQL / MySQL / SQLite
- • Snowflake / BigQuery / Redshift
- • Oracle / SQL Server / ClickHouse
- • DuckDB(嵌入式分析)
️ 5 分钟快速上手
安装
pip install 'vanna[all]'# 或者最小安装pip install vanna最简示例(30 秒跑通)
import vanna as vn# 配置 LLM(支持任意模型)vn.configure_llm( api_key="sk-...", model="gpt-4o")# 配置数据库vn.connect_to_sqlite("https://vanna.ai/Chinook.sqlite")# 训练(喂 DDL + 文档 + 问答对)vn.train(ddl=""" CREATE TABLE Artist ( ArtistId INTEGER PRIMARY KEY, Name NVARCHAR(120) );""")# 自然语言提问vn.ask("前 10 名最受欢迎的艺术家的专辑数量是多少?")输出效果:
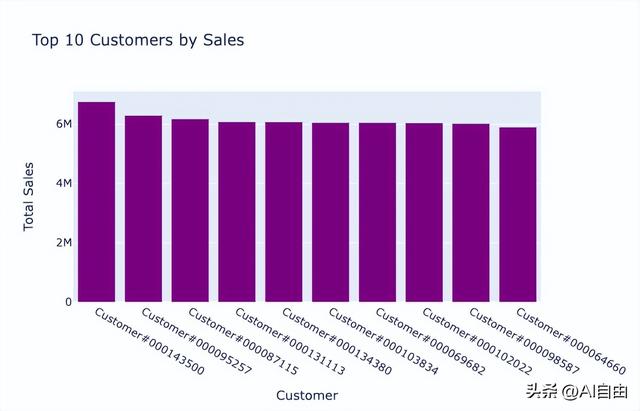
返回结果包含三部分:① SQL 代码块 ② 交互式数据表 ③ Plotly 柱状图。
进阶:使用本地 Ollama(完全离线)
from vanna.ollama import Ollamafrom vanna.chromadb import ChromaDB_VectorStoreclass MyVanna(ChromaDB_VectorStore, Ollama): def __init__(self): ChromaDB_VectorStore.__init__(self) Ollama.__init__(self, model="qwen2.5:7b")vn = MyVanna()vn.connect_to_postgres( host="localhost", dbname="mydb", user="readonly", password="xxx")vn.train(question="上个月销量", sql="SELECT SUM(amount) FROM orders WHERE ...")result = vn.ask("上个月销量")注意:本地模型准确率比 GPT-4 低 10-15%,生产环境建议用 GPT-4o / Claude 3.5,本地 Ollama 适合开发调试。
与竞品对比
维度Vanna 2.0WrenAISQLBotLangChain SQL Agent架构Agentic RAGRAG + CoT规则模板Tool-calling Agent准确率85%+75%60%50-70%Web UI✅ 预构建组件✅ 自带界面⚠️ 简单❌ 无行级权限✅ 内置⚠️ 需定制❌ 无❌ 无审计日志✅ 内置⚠️ 需定制❌ 无❌ 无本地 LLM✅ Ollama✅ Ollama❌ 仅云端✅ 任意多数据库✅ 12+ 种✅ 8+ 种⚠️ 3 种✅ 任意流式输出✅ SSE❌ 一次性❌ 一次性⚠️ 需自实现学习曲线中中低高Star 数23.6k1.2k1.5k95k+
总结:
- • 想 快速跑通 PoC → SQLBot(但功能有限)
- • 想 企业级生产部署 → Vanna 2.0(行级权限 + 审计 + 预构建 UI)
- • 想 自建 Agent 链 → LangChain SQL Agent(灵活但工作量大)
- • 想 纯本地 + 中文友好 → WrenAI
适用场景
场景 1:业务自助分析(解放数据团队)
痛点:销售总监要"上周华东区 Top 10 客户"的数据,要提需求 → 等排期 → 数据工程师写 SQL → BI 出报表,周期 1-3 天。
Vanna 2.0 解法:
- 1. 数据团队提前训练 Vanna(喂表结构、术语、业务规则)
- 2. 销售总监登录 Web 界面 → 直接打字提问
- 3. 30 秒内得到 SQL + 表格 + 图表
实际效果:某 SaaS 公司部署后,数据团队的临时取数工单减少 70%。
场景 2:客户成功团队(高安全等级)
痛点:CSM 需要查"我负责的客户的健康分",但不能看其他 CSM 的客户——传统 SQL Agent 写出的 SQL 不带权限过滤,存在数据泄露风险。
Vanna 2.0 解法:
# 配置时注入用户身份vn.set_user_context( user_id="csm_001", role="customer_success", permissions={"region": "APAC", "tier": ["gold", "platinum"]})# 业务人员问"上个月流失风险高的客户"# Vanna 自动追加 WHERE region='APAC' AND tier IN ('gold','platinum')权限在 SQL 生成阶段就注入,绕过 LLM 直接拼接的风险。
场景 3:金融/医疗合规(审计 + 限流)
需求:所有查询必须按用户记录日志,敏感表查询必须经审批,单个用户每分钟最多 10 次查询。
Vanna 2.0 配置:
from vanna.lifecycle import LifecycleHookclass ComplianceHook(LifecycleHook): async def before_query(self, user, sql): if "pii_" in sql or "patient_" in sql: await self.request_approval(user, sql) async def after_query(self, user, sql, result): await self.audit_log.write( user_id=user.id, sql=sql, rows=len(result), timestamp=now() )vn.register_hook(ComplianceHook())用户群体总结
- • ✅ 业务分析师:不再排队等数据团队,30 秒自助取数
- • ✅ 数据工程师:从"写 SQL 工单"解放出来,专注建模和训练 Vanna
- • ✅ CSM / 销售:带权限隔离的客户查询工具
- • ✅ 金融/医疗:审计 + 限流 + 行级权限,满足合规
- • ❌ 不适合:需要秒级响应的 OLTP 场景(Vanna 走 LLM 推理,延迟 2-10 秒)
总结
Vanna 2.0 不是又一个"AI 写 SQL"的玩具,而是把 Agentic RAG + 企业级安全 + 预构建 UI 三件事打包好的 Text-to-SQL 平台。
23,600+ Star、2,400+ Fork、12+ 数据库、6+ LLM、MIT 开源、预构建 Web 组件、内置行级权限和审计日志——这些组合在一起,让 Vanna 2.0 成为 2025-2026 年企业 Text-to-SQL 场景的事实标准之一。
推荐指数: ⭐⭐⭐⭐⭐(满分 5 星)
适合人群:
- • 想让业务团队自助取数的 Data Leader
- • 需要带权限隔离的企业 IT 团队
- • 想用本地 LLM 跑 SQL 转换的隐私敏感行业
立即体验:
- • 官方文档:https://vanna.ai/docs/
- • GitHub:https://github.com/vanna-ai/vanna
- • 视频演示:https://vanna.ai/
开源协议: MIT
数据截至 2026-06-14,Vanna 2.0 已发布生产版本。最新信息请以 GitHub 仓库为准。